第五届中间件性能挑战赛
今年参与了阿里巴巴举办的 中间件性能挑战赛,并且有幸进入到了复赛,虽然后期由于其他原因没法专心参与,不过通过这次比赛也让我在技术上收获了不少,这边小小的做下本次比赛的总结。
初赛:《自适应负载均衡的设计实现》
赛题分析
初赛的题目是在 Dubbo 之上进行的插件开发,对参与者对于 Dubbo 的调用过程有一定的要求。官方在 gateway 端提供了 CallbackListenerImpl、TestClientFilter、UserLoadBalance 供开发。在 provider 端提供了 CallbackServiceImpl、TestRequestLimiter、TestServerFilter 供开发。
将这些组件结合起来就形成了基本的调用链路。
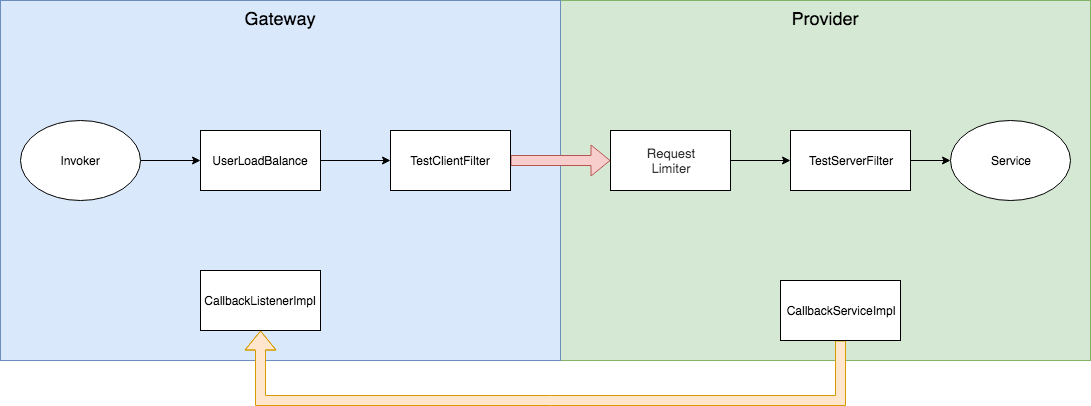
目标
-
provider 在接收请求大于处理线程池大小的时候,将会执行拒绝策略 AbortPolicyWithReport,并将线程栈信息以日志文件输出。这无疑增加了服务端的压力,那么就需要让 provider 在 TestRequestLimiter 进行限流,在剩余线程数量不足时拒绝进来的请求。
-
要完成自适应的负载均衡,那么就需要由 provider 端将权重推送至 gateway,这项工作通过 CallbackServiceImpl 和 CallbackListenerImpl 来完成。但是传输的数据为字符串,不包含 provider 标识,这时就需要能够获取 provider 的服务地址,连带指标推送给 gateway。
-
gateway 接收到请求时选择性能最优 provider,当所有 provider 压力均满时直接拒绝请求。
设计与实现
provider 拒绝服务
通过分析 AllChannelHandler 的源码发现,provider 在通过 Filter 后才会使用线程池处理请求,为了不让服务进入拒绝策略,就需要在线程池不足时利用 Filter 拒绝他。官方是允许使用 SPI 的,那么可根据 WrappedChannelHandler 的代码,从 DataStore 里获取所使用的线程池,提取出线程池最大线程数,在请求前后进行计数,拦截超出能力的请求。
public class WrappedChannelHandler implements ChannelHandlerDelegate {
public WrappedChannelHandler(ChannelHandler handler, URL url) {
this.handler = handler;
this.url = url;
executor = (ExecutorService) ExtensionLoader.getExtensionLoader(ThreadPool.class)
.getAdaptiveExtension().getExecutor(url);
String componentKey = Constants.EXECUTOR_SERVICE_COMPONENT_KEY;
if (Constants.CONSUMER_SIDE.equalsIgnoreCase(url.getParameter(Constants.SIDE_KEY))) {
componentKey = Constants.CONSUMER_SIDE;
}
DataStore dataStore = ExtensionLoader.getExtensionLoader(DataStore.class).getDefaultExtension();
dataStore.put(componentKey, Integer.toString(url.getPort()), executor);
}
...
}
经过了这一层拦截,分数就已经明显上去了,但是由于 provider 的能力各不相同,还需要通过计算权重进行请求分发。
数据通信
当消费方与多个服务方都需要进行通信时,能够唯一确定数据的来源是关键,还是通过读源码,我发现能够从服务 URL 中获取到主机地址和端口号。在 provider 端,自定义暴露监听器保存系统的地址。在 gateway 端,自定义引用监听器将 URL 与地址进行一一映射。
// gateway
public class InvokerMapperListener implements InvokerListener {
private static final Map<URL, String> addressMapper = new ConcurrentHashMap<>();
@Override
public void referred(Invoker<?> invoker) throws RpcException {
URL url = invoker.getUrl();
String address = getAddress(url);
addressMapper.put(url, address);
}
}
// provider
public class ThreadPoolExporterListener implements ExporterListener {
@Override
public void exported(Exporter<?> exporter) throws RpcException {
if (Context.ADDRESS != null) {
return;
}
URL url = exporter.getInvoker().getUrl();
Context.ADDRESS = getAddress(url);
}
}
public static String getAddress(URL url) {
String ip = url.getParameter(Constants.BIND_IP_KEY);
String port = url.getParameter(Constants.BIND_PORT_KEY);
return ip + ":" + port;
}
通信功能算是完成了,这时可以直接使用前面 provider 获取到的线程池大小作为权重,但是由于服务能力是动态变化的,为了达到更好的效果还需要进一步改进。
动态负载
根据评测代码可知,消费服务在程序内部使用了 Semaphore 对请求进行了拦截,实际可容纳的请求小于线程数,并且并发数随着时间也在发生变化。
如果单位时间内接收的请求数大于实际并发数时,则多余的请求将会被置为等待状态。当请求数持续大于并发数时,会导致请求堆积造成大量超时。因此在 Dubbo 中有个超时检测机制 org.apache.dubbo.remoting.exchange.support.DefaultFuture##TIME_OUT_TIMER,这是一个用于中止任务的时间轮,当一个请求进入执行阶段时,它将会被放入时间轮,在一定时间后结束请求返回错误信息。
因此需使得请求在时间轮触发之前执行,这样才能保证不会造成异常响应。在这里我还是使用到了前面获取的线程池,由于线程在线程池中空闲的状态为 WAITING 或 TIMED_WAITING,在执行过程中工作线程的状态可能为 RUNNABLE、BLOCKED、WAITING、TIMED_WAITING,空闲线程与工作线程存在状态重叠,因而无法将 getActiveCount 用作并发数。
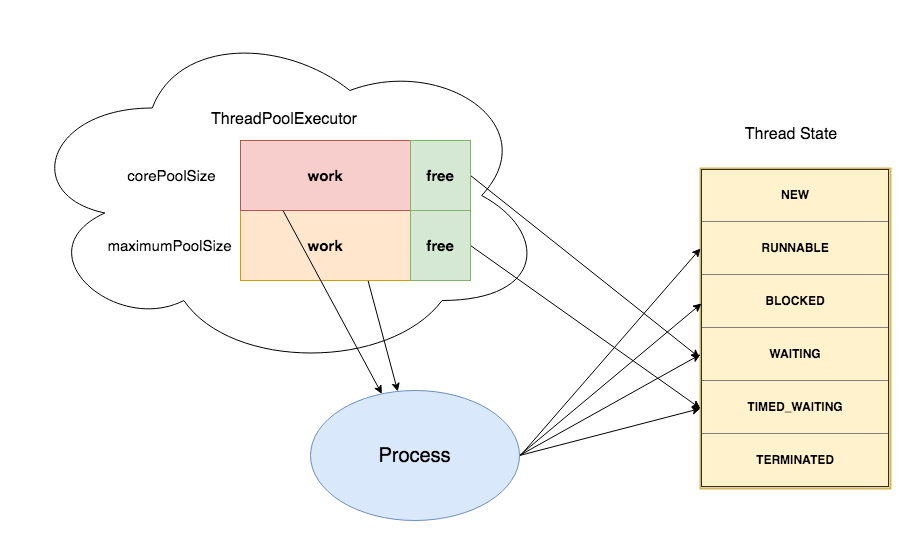
因此在执行阶段 Filter 前后对当前线程进行标记,并放入一个 placeHolder 中保存,在退出 Filter 时移除标记。由此一来 placeHolder 中就只存在工作中的线程,在除去 BLOCKED 和 WAITING 状态的线程即为并发数。
为了避免并发冲突影响效率,采用无锁编程,预先创建好数组,利用线程id作为下标指定标记元素位置。
在得到实际并发数后,再通过与 cpu核心数、cpu频率 进行计算得出权重值,定时的发送给 gateway 用于选择最优 provider。
gateway 将收到并发数作为负载均衡还远远不够,如果一个服务由于机器资源不足、网络故障等原因也将会导致请求异常,因此请求耗时也是一个考量负载的指标。由于网络消耗的存在,则在 gateway 端做请求耗时的收集,将并发数与耗时进行结合完成负载均衡策略。

复赛:《实现一个进程内基于队列的消息持久化存储引擎》
赛题分析
赛题要求实现一个进程内消息持久化的存储引擎,提供了 4g 的堆内存,2g 的堆外内存,300g 的SSD磁盘。过程分别为发送、查询聚合消息、查询聚合结果,串行执行三个步骤,每个步骤需要在 30 分钟内完成,以每个阶段的 发送数\时间 总和为成绩。
设计
-
由于查询阶段需要对 时间戳 和 数值 进行条件过滤,考虑以 时间戳 和 数值 创建索引键对数据分散进行存储,以数据块为存储单位。
-
每个线程所发送消息的时间戳是递增的,对查询过滤天然适合,则为每个线程映射一个存储组件实例。
-
官方提供使用的存储介质为 SSD磁盘,大量数据写入的效率好,所以将数个数据块为一组单位,缓存于内存中,在写入数据达到下一组单位时进行文件存储。
-
在查询阶段为了更好的利用资源,使用 lru缓存 保存查询数据。

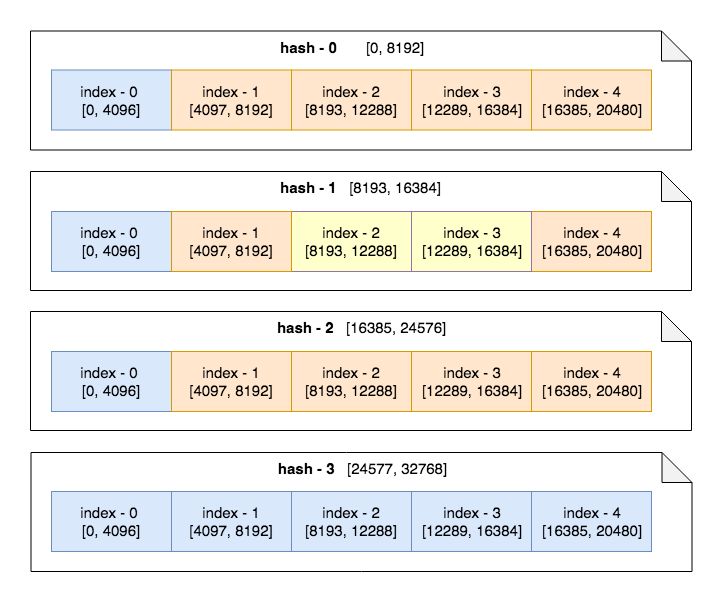
发送阶段完成后磁盘文件组织如下,以时间戳定位文件,再以数值选择文件内的数据块(图中以 8192 为时间戳分片大小,4096 为数值为片大小,均为 2 的幂次方,以位运算即可完成路由)。

如查询条件为 { t: [8000, 22000], a: [5000, 20000] },则选择文件 hash-0、hash-1、hash-2 为目标文件,分别对文件内的 index-1、index-2、index-3、index-4 数据块进行检索,其中 hash-1 index-2、hash-1 index-3 为中间数据,无需对数据进行条件过滤。
实现
其实复赛的设计思路并不难,主要的难点是分片大小的选择,如何更好的利用内存不发生 OOM,以及利用多线程提升效率。
在写入阶段,使用内存进行数据的缓存,利用时间戳的有序性检测是否进入下个文件数据集,由于需要对全量数据都进行哈希,采用了位移操作提升效率。
在读取阶段,对条件使用哈希确定目标数据的分布范围,充分利用堆内存与堆外内存,将分配的 ByteBuffer 进行缓存,提高下次查询时的效率。同理,对于无需条件过滤的结果也可以通过缓存来提高效率。
增加了缓存就需要考虑内存容量问题,为了避免 OOM 需要引入淘汰规则。直接使用 SoftReference 容易频繁产生 CMS GC,影响查询效率,而使用 WeakReference 缓存数据则具有不确定性,数据很可能被快速回收,失去了缓存的意义。
经过分析后选择了LRU算法,在固定大小集合里缓存数据,对长久未使用的数据进行清理。传统的 LRU Cache 可用继承 LinkedHashMap 的方式实现,然而这个类是非线程安全的,在查询场景可能产生并发问题,因此重新实现了一个线程安全的 LRU Cache。
public class ConcurrentLRUCache<K, V> {
private final Queue<K> keySet;
private final Map<K, T> cache;
private final AtomicInteger acquire;
private final int outSize;
private volatile boolean full = false;
public ConcurrentLRUCache(int size) {
this.keySet = new ConcurrentLinkedQueue<>();
this.cache = new ConcurrentHashMap<>(size, 1f);
this.acquire = new AtomicInteger(size);
this.outSize = size + 1;
}
public void put(K key, T value) {
if (full) {
K firstKey = keySet.poll();
cache.remove(firstKey);
} else {
int nextSize = acquire.incrementAndGet();
if (nextSize > outSize) {
Thread.yield();
put(key, value);
return;
}
if (nextSize == outSize) {
full = true;
}
}
cache.put(key, value);
keySet.offer(key);
}
public T get(K key) {
T value = cache.get(key);
if (value == null) {
return null;
}
if (keySet.remove(key)) {
keySet.offer(key);
}
return value;
}
}
除了添加缓存外,还有其他优化手段,比如 多线程并发处理数据块、对分块数据进行压缩、数据与消息体分开存储、利用时间戳的顺序中断查询。
总结
在这次比赛中,主要收获了在系统设计上的锻炼,分析问题也更加全面了,以及在 无锁编程、NIO处理、编写高性能代码 方面的进步。如通过 async-profiler 发现乐观锁在大量请求下的性能问题,并转变思路使用无锁编程。了解到 MappedByteBuffer 在大量写入的情况下会频繁发生 pageCache 的 flush,可以先准备好 ByteBuffer 保存数据,之后再将整个 ByteBuffer 写入到 MappedByteBuffer 中。